The AI Agent Ecosystem
The landscape of AI agents—autonomous software entities that perform tasks on behalf of users or other programs—has been rapidly evolving. While numerous frameworks and categorizations, such as agent stacks and market maps, attempt to outline this ecosystem, they often fall short of capturing the real-world usage patterns observed by developers. This discrepancy arises because the AI agent ecosystem is dynamic, with significant advancements occurring in areas like memory management, tool utilization, secure execution, and deployment strategies. To address these changes and provide a more accurate representation, experts with extensive experience in open-source AI development and AI research have proposed their own “agent stack.”
Existing Categorizations: Agent Stack and Market Maps
Agent Stack: Traditionally, an agent stack might layer different components required for AI agents to function, such as:
- Foundation Models: Core AI models (e.g., GPT-4) that provide the fundamental capabilities.
- Middleware: Tools and libraries that facilitate communication between models and applications.
- Applications: End-user applications leveraging the above layers to deliver functionality.
Market Maps: These maps categorize AI agents based on their applications or industries, such as:
- Customer Service Agents: Chatbots handling customer inquiries.
- Productivity Agents: Tools like scheduling assistants.
- Creative Agents: Systems aiding in content creation.
Why the Discrepancy?
While these categorizations provide a broad overview, they often miss the nuanced ways developers integrate and utilize AI agents in real-world applications. The rapid advancements in the ecosystem have outpaced these frameworks, leading to gaps between theoretical models and practical implementations.
Recent Developments in the AI Agent Ecosystem
- Memory Management:
- Example: Traditional AI agents process information in real-time without retaining context. Modern agents now incorporate memory modules that allow them to remember past interactions, leading to more coherent and context-aware responses. For instance, an AI writing assistant can recall previous sections of a document to maintain consistency.
- Tool Usage:
- Example: AI agents are increasingly leveraging external tools and APIs to extend their capabilities. A virtual assistant might integrate with calendar APIs to schedule meetings or use translation services to communicate in multiple languages.
- Secure Execution:
- Example: As AI agents handle sensitive data, ensuring secure execution becomes paramount. Techniques like sandboxing and encryption are employed to protect data integrity and privacy. For instance, an AI medical assistant must securely handle patient records to comply with regulations like HIPAA.
- Deployment Strategies:
- Example: Deployment has evolved from simple cloud-based models to more sophisticated architectures like edge computing. An AI-powered IoT device might process data locally to reduce latency and enhance privacy, while still syncing with cloud services for broader analytics.
LLMs → Frameworks → Actionable Agents
The evolution from LLMs to LLM agents represents a significant leap in the application of AI technology. Let's break this progression down step-by-step
LLMs
LLMs like GPT-3, GPT-4, and others are pre-trained AI models designed to process and generate human-like text based on input prompts. They are essentially reactive systems that output answers or generate content directly related to the provided input.
Example:
- Input: "Write a poem about the sea."
- Output: "The sea is deep, the waves do leap, beneath the moon’s glow, secrets they keep..."
Here, the LLM passively generates output without awareness of tasks, tools, or broader objectives.
Frameworks or SDKs
Frameworks and tools like LangChain and LlamaIndex introduced a structured way to integrate LLMs with external tools, datasets, and pipelines. These allowed developers to chain together tasks and provide contextual memory, making LLMs more effective for complex applications.
Actionable Agents
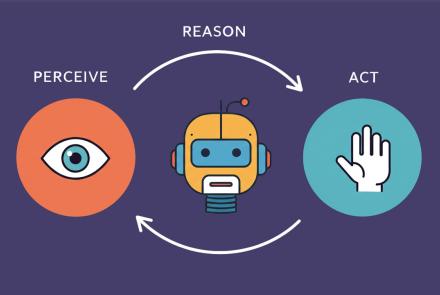
LLM agents take this concept further by introducing autonomy, decision-making, and goal-oriented behavior. Agents are not just reactive; they are proactive systems that can execute sequences of actions, make decisions based on intermediate outputs, and manage memory to track long-term goals. They combine tools usage, autonomy, and memory to behave more like intelligent assistants or autonomous agents.
Key Features of LLM Agents:
- Tool Use: Agents can call APIs, retrieve and process information, or control other systems.
- Autonomous Execution: They decide the next course of action without continuous user input.
- Memory: They retain past interactions or steps to inform future decisions.
Example:
- Scenario: A user asks the agent, "Help me plan a vacation to Paris."
- Agent Workflow:
- Step 1: Retrieve weather data for Paris to recommend the best travel dates.
- Step 2: Search for flights and hotels within the user's budget.
- Step 3: Recommend a list of activities (using travel APIs).
- Step 4: Ask the user for preferences and adjust the plan dynamically.
This agent operates autonomously, selecting and executing actions across multiple steps without requiring the user to specify each one explicitly.
The Agents Stack:
The move from LLMs to agents necessitated new components in the AI ecosystem:
- Task Planning and Management: To break down complex goals into smaller tasks.
- Tool Integration: For actions like web searches, API calls, and database queries.
- Long-Term Memory: To retain context and continuity across sessions.
- Execution Frameworks: To allow autonomous workflows (e.g., OpenAI Functions, LangChain agents).
Example:
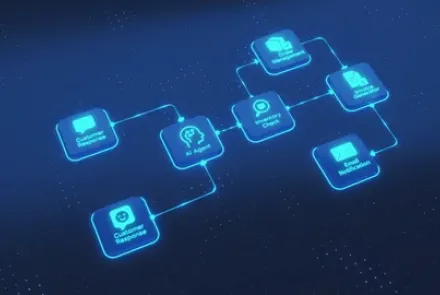
A customer service agent powered by an LLM agent stack:
- Customer Query: "I received a damaged product. What should I do?"
- Agent Workflow:
- Look up the order details from a database.
- Determine the company’s refund or replacement policy.
- Generate and send a replacement order automatically.
- Notify the user about the next steps.
The agent autonomously executes all steps while maintaining a coherent conversation.
The Shift in 2024:
By 2024, the focus has shifted to compound systems that combinations of multiple LLM agents, traditional software, and human oversight. These systems are used for complex tasks such as:
- Multi-agent collaboration for problem-solving.
- Integrating agents into larger enterprise workflows.
- Building AI-powered assistants for specialized domains (e.g., law, medicine, finance).